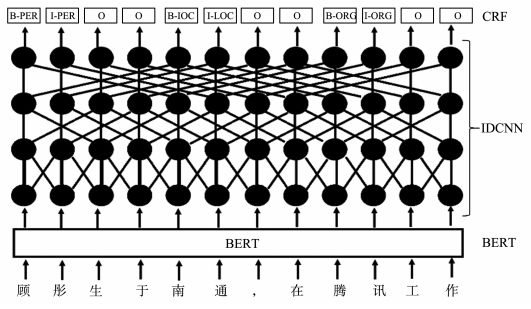
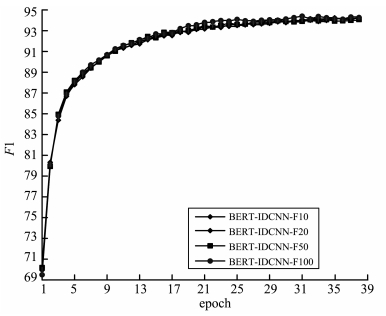
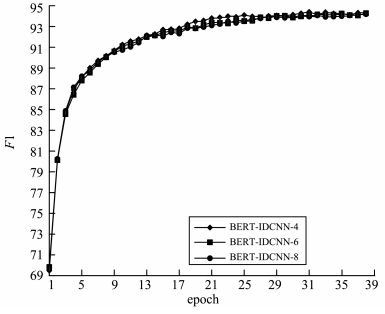
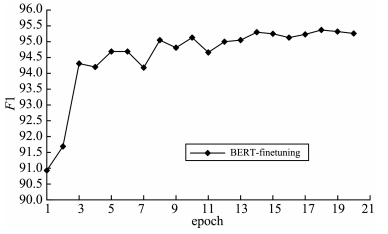
预训练语言模型能够表达句子丰富的句法和语法信息,并且能够对词的多义性建模,在自然语言处理中有着广泛的应用,BERT(bidirectional encoder representations from transformers)预训练语言模型是其中之一。在基于BERT微调的命名实体识别方法中,存在的问题是训练参数过多,训练时间过长。针对这个问题提出了基于BERT-IDCNN-CRF(BERT-iterated dilated convolutional neural network-conditional random field)的中文命名实体识别方法,该方法通过BERT预训练语言模型得到字的上下文表示,再将字向量序列输入IDCNN-CRF模型中进行训练,训练过程中保持BERT参数不变,只训练IDCNN-CRF部分,在保持多义性的同时减少了训练参数。实验表明,该模型在MSRA语料上F1值能够达到94.41%,在中文命名实体任务上优于目前最好的Lattice-LSTM模型,提高了1.23%;与基于BERT微调的方法相比,该方法的F1值略低但是训练时间大幅度缩短。将该模型应用于信息安全、电网电磁环境舆情等领域的敏感实体识别,速度更快,响应更及时。
关键词:中文命名实体识别
;
BERT模型
;
膨胀卷积
;
条件随机场
;
信息安全
Abstract
The pre-trained language model, BERT (bidirectional encoder representations from transformers), has shown promising result in NER (named entity recognition) due to its ability to represent rich syntactic, grammatical information in sentences and the polysemy of words. However, most existing BERT fine-tuning based models need to update lots of model parameters, facing with expensive time cost at both training and testing phases. To handle this problem, this work presents a novel BERT based language model for Chinese NER, named BERT-IDCNN-CRF (BERT-iterated dilated convolutional neural network-conditional random field). The proposed model utilizes traditional BERT model to obtain the context representation of the word as the input of IDCNN-CRF. At training phase, the model parameters of BERT in the proposed model remain unchanged so that the proposed model can reduce parameters training while maintaining polysemy of words. Experimental results show that the proposed model obtains significant training time with acceptable test error.
Keywords:NER in Chinese
;
BERT
;
IDCNN
;
CRF
;
information security
LI Ni, GUAN Huan-mei, YANG Piao, DONG Wen-yong. BERT-IDCNN-CRF for named entity recognition in Chinese. Journal of Shandong University(Natural Science)[J], 2020, 55(1): 102-109 doi:10.6040/j.issn.1671-9352.2.2019.076
HAMMERTON J. Named entity recognition with long short-term memory[C]// Conference on Natural Language Learning at HLT-NAACL. NJ: Association for Computational Linguistics, 2003.
DONGC H, ZHANGJ J, ZONGC Q, et al. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition[M]. Cham: Springer, 2016: 239- 250.
HE J, WANG H. Chinese named entity recognition and word segmentation based on character[C]// Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing.[S.l.]: [s.n.], 2008.
LIU Z X, ZHU C H, ZHAO T J. Chinese named entity recognition with a sequence labeling approach: based on characters, or based on words?[M]//Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence. Berlin: Springer, 2010: 634-640.
LI H, HAGIWARA M, LI Q, et al. Comparison of the impact of word segmentation on name tagging for Chinese and Japanese[C]// LREC.[S.l.]: [s.n.], 2014: 2532-2536.
CHEN W, ZHANG Y, ISAHARA H. Chinese named entity recognition with conditional random fields[C] // Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing.[S.l.]: [s.n.], 2006: 118-121.
ZHAO H, KIT C. Unsupervised segmentation helps supervised learning of character tagging for word segmentation and named entity recognition[C]// Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing. Berlin: Springer, 2008.
PENG N, DREDZE M. Named entity recognition for Chinese social media with jointly trained embeddings[C] // Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. PA: Association for Computational Linguistics, 2015: 548-554.
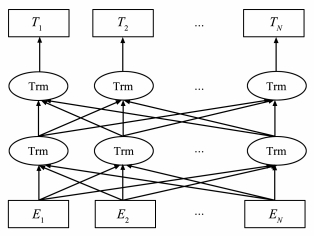
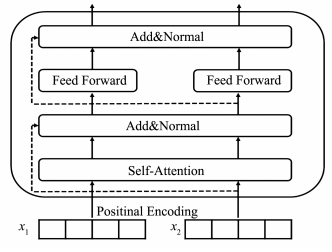
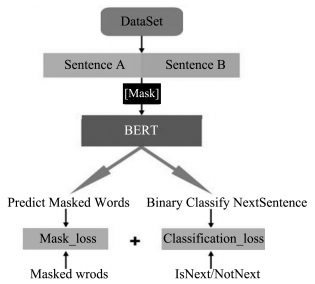
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J/OL]. arXiv: 1810.04805[cs], 2018.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}