《山东大学学报(理学版)》 ›› 2020, Vol. 55 ›› Issue (7): 81-87.doi: 10.6040/j.issn.1671-9352.1.2019.048
王佳麒( ),杨沐昀*(),赵铁军,赵臻宇
),杨沐昀*(),赵铁军,赵臻宇
Jia-qi WANG(),Mu-yun YANG*(),Tie-jun ZHAO,Zhen-yu ZHAO
摘要:
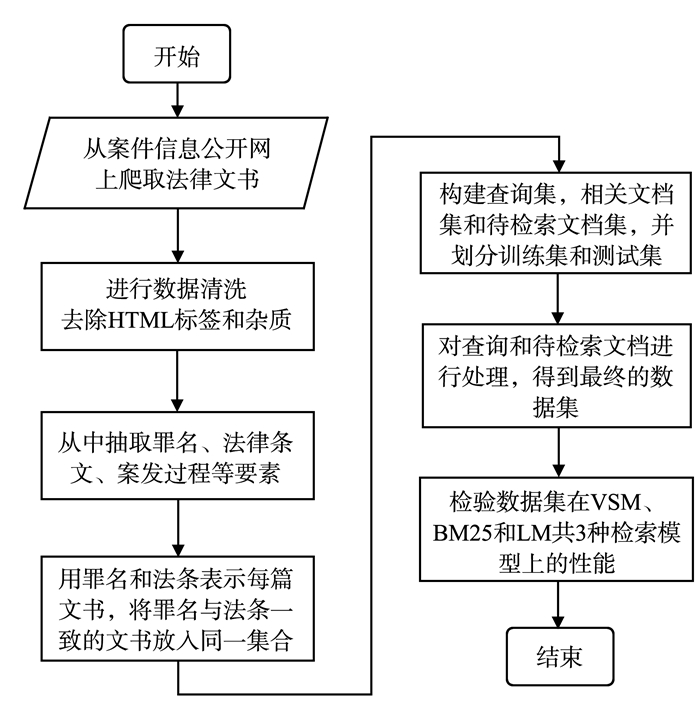
智慧检务是进一步发展检察信息化的重要步骤,它的实施和普及能更好地提升检察院工作质量和工作效率。实际上,检察官在办公流程中往往会处理大量的检察院法律文书,若不能有效地组织和利用这些文书中的信息,会降低其工作效率,信息检索技术恰好可以解决这一问题。在法律领域,中文信息检索数据集的缺失在一定程度上制约了法律信息检索的发展。在这一背景下,针对检察院法律文书的特点,提出了一种构建检察院法律文书检索数据集的方法,并构建了一个可用于法律领域信息检索研究的小型中文数据集。通过实验分析,验证了该数据集在不同检索模型上的性能。
中图分类号:
| 1 | 中华人民共和国科学技术部.关于对国家重点研发计划"公共安全风险防控与应急技术装备"重点专项(司法专题任务)2018年度第二批项目申报指南征求意见的通知[EB/OL].(2018-02-08) [2019-05-20].http://www.most.gov.cn/tztg/201802/t20180208_138083.htm. |
| 2 |
CLEVERDON C W . The Cranfield tests on index language devices[J]. Aslib Proceedings, 1967, 19 (6): 173- 194.
doi: 10.1108/eb050097 |
| 3 | National Insitiute of Standards and Technology.TREC (Text REtrieval Conference)[OB/OL]. (2017-12-21)[2019-05-20].https://trec.nist.gov/. |
| 4 |
LIU Yiqun , ZHANG Min , CEN Rongwei , et al. Data cleansing for web information retrieval using query independent features[J]. Journal of the American Society for Information Science and Technology, 2007, 58 (12): 1884- 1898.
doi: 10.1002/asi.20633 |
| 5 | 李静静, 闫宏飞. 中文网页信息检索测试集的构建、分析及应用[J]. 中文信息学报, 2008, 22 (1): 30- 36. |
| LI Jingjing , YAN Hongfei . Chinese web retrieval test collections: construction, analysis and application[J]. Journal of Chinese Information Processing, 2008, 22 (1): 30- 36. | |
| 6 | 徐建民, 王平. 小型中文信息检索测试集的构建与分析[J]. 情报杂志, 2009, 28 (1): 13- 16. |
| XU Jianmin , WANG Ping . Small Chinese information retrieval test collentions: construction and analysis[J]. Journal of Intelligence, 2009, 28 (1): 13- 16. | |
| 7 | FOX E A. Characterization of two new experimental collections in computer and information science contatining textual and bibliographic concepts[J]. Cornell University, 1983, Technical Report 83-561. |
| 8 | HERSH W, BUCKLEY C, LEONE T J, et al. OHSUMED: an interactive retrieval evaluation and new large test collection for research[C]//SIGIR′94. London: Springer, 1994: 192-201. |
| 9 | National Insitiute of Standards and Technology. TREC legal track[EB/OL]. (2012-05-10)[2019-05-20]. https://trec-legal.umiacs.umd.edu/. |
| 10 | XIAO Chaojun, ZHONG Haoxi, GUO Zhipeng, et al. Cail2018: a large-scale legal dataset for judgment prediction[J]. arXiv, 2018, arXiv: 1807.02478. |
| 11 | CORMACK G V, PALMER C R, CLARKE C L A. Efficient construction of large test collection[C]//Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Melbourne: ACM, 1998: 282-289. |
| 12 |
SALTON G , WONG A , YANG C S . A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18 (11): 613- 620.
doi: 10.1145/361219.361220 |
| 13 | PONTE J M, CROFT W B. A language modeling approach to information retrieval[C]//ACM SIGIR Forum. New York: ACM, 2017: 202-208. |
| [1] | 王凯,洪宇,邱盈盈,王剑,姚建民,周国栋. 一种查询意图边界检测方法研究[J]. 山东大学学报(理学版), 2017, 52(9): 13-18. |
| [2] | 曹蓉,黄金柱,易绵竹. 信息检索—DARPA人类语言技术研究的最终指向[J]. 山东大学学报(理学版), 2016, 51(9): 11-17. |
| [3] | 孟烨,张鹏,宋大为. 探索数据集特征与伪相关反馈的平衡参数之间的关系[J]. 山东大学学报(理学版), 2016, 51(7): 18-22. |
| [4] | 张文雅,宋大为,张鹏. 面向垂直搜索基于本体的可读性计算模型[J]. 山东大学学报(理学版), 2016, 51(7): 23-29. |
| [5] | 李胜东, 吕学强, 孙军, 施水才. Lucene全文索引效率的改进[J]. 山东大学学报(理学版), 2015, 50(07): 76-79. |
| [6] | 许洁萍1,殷宏宇1,范子文2. 基于近似子乐句的翻唱歌曲识别研究[J]. J4, 2013, 48(7): 68-71. |
| [7] | 孙静宇,陈俊杰,余雪丽,李鲜花. 协同Web搜索综述[J]. J4, 2011, 46(5): 9-15. |
| [8] | 庞观松,张黎莎,蒋盛益*,邝丽敏,吴美玲. 一种基于名词短语的检索结果多层聚类方法[J]. J4, 2010, 45(7): 39-44. |
| [9] | 高 翔,王 敏 . 模糊聚类算法在Web信息搜索中的应用[J]. J4, 2006, 41(3): 11-12 . |
| [10] | 付雪峰,刘邱云,王明文 . 基于互信息的粗糙集信息检索模型[J]. J4, 2006, 41(3): 116-119 . |
| [11] | 宋春芳,石冰 . 一种基于关联规则的搜索引擎结果聚类算法[J]. J4, 2006, 41(3): 61-65 . |
| [12] | 何 靖 . 一种问答式检索系统布尔查询生成方法[J]. J4, 2006, 41(3): 13-17 . |
| [13] | 万海平,何华灿 . 基于谱图的维度约简及其应用[J]. J4, 2006, 41(3): 58-60 . |
| [14] | 王太峰,袁平波,荚济民,俞能海 . 基于新闻环境的人物肖像检索[J]. J4, 2006, 41(3): 5-10 . |
| [15] | 胡俊刚,董守斌,陈晓志,张元丰 . 基于URL类型优先级的入口页面查询算法[J]. J4, 2006, 41(3): 76-80 . |
|