《山东大学学报(理学版)》 ›› 2019, Vol. 54 ›› Issue (5): 37-43.doi: 10.6040/j.issn.1671-9352.2.2018.136
卢政宇( ),李光松,申莹珠,张彬
),李光松,申莹珠,张彬
Zheng-yu LU(),Guang-song LI,Ying-zhu SHEN,Bin ZHANG
摘要:
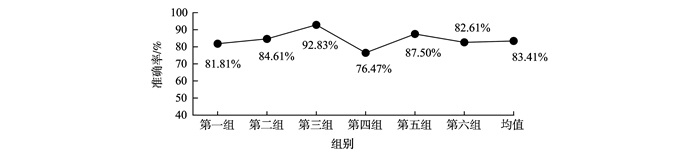
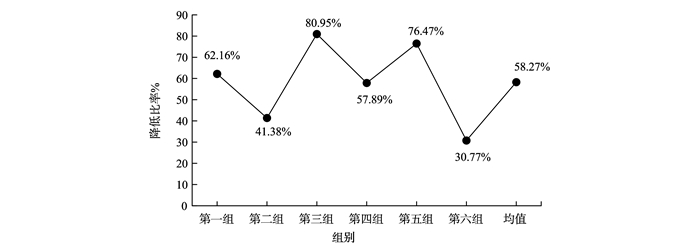
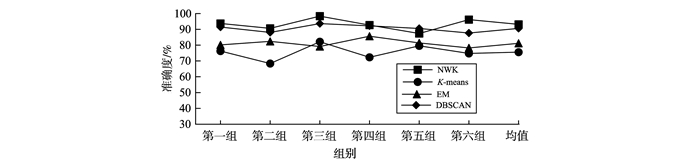
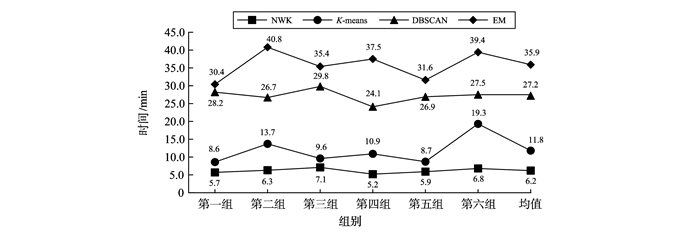
对未知协议消息序列进行聚类处理是分析协议格式的基础。从字符串匹配的角度出发,利用协议格式字段的连续性,在传统K-均值算法基础上提出一种基于连续特征的未知协议消息聚类算法。首先基于协议格式字段连续性对待测数据集进行粗聚类,提取出K-均值算法的初始聚类中心,再使用消息距离及收敛函数改进的迭代算法对数据进行迭代处理实现消息的进一步聚类。实验表明,提出的新方法与传统K-均值算法相比,在聚类准确度上提升了17.58%,迭代次数上减少了约58.27%,与EM算法、DBSCAN算法相比在聚类准确率与时间上均有明显提升。
中图分类号:
| 1 | 吴礼发, 洪征, 潘璠. 网络协议逆向分析及应用[M]. 北京: 国防工业出版社, 2016. |
| WU Lifa , HONG Zheng , PAN Pan . Network protocol reverse analysis and application[M]. Beijing: National Defense Industry Press, 2016. | |
| 2 | MACQUEEN J. Some methods for classification and analysis of multivariate observations[J]. Proc of Berkeley Symposium on Mathematical Statistics & Probability. Berkley: California Press, 1965: 281-297. |
| 3 |
NEEDLEMAN S B , WUNSCH C D . A general method applicable to the search for similarities in the amino acid sequence of two proteins[J]. Journal of Molecular Biology, 1970, 48 (3): 443- 453.
doi: 10.1016/0022-2836(70)90057-4 |
| 4 | CUI W, KANNAN J, WANG H J. Discoverer: automatic protocol reverse engineering from network traces[C]//Proceedings of 16th USENIX Security Symposium, Boston: Usenix Security, 2007. |
| 5 | HUANG Q, LEE P P C, ZHANG Z B. Exploiting intra-packet dependency for fine-grained protocol format inference[C]//2015 IFIP Networking Conference Toulouse: IEEE, 2015: 1-9. |
| 6 | SIJA B D , GOO Y H , SHIM K S , et al. A survey of automatic protocol reverse engineering approaches, methods, and tools on the inputs and outputs view[J]. Security and Communication Networks, 2018, 2018: 1- 17. |
| 7 |
何超, 刘方, 曾曦, 等. 针对未知协议消息序列的聚类分析实现[J]. 通信技术, 2017, 50 (2): 277- 286.
doi: 10.3969/j.issn.1002-0802.2017.02.014 |
|
HE Chao , LIU Fang , ZENG Xi , et al. Clustering analysis of unknown protocol message sequence[J]. Communications Technology, 2017, 50 (2): 277- 286.
doi: 10.3969/j.issn.1002-0802.2017.02.014 |
|
| 8 |
GUSFIELD Dan . Algorithms on stings, trees, and sequences[J]. ACM SIGACT News, 1997, 28 (4): 41- 60.
doi: 10.1145/270563 |
| 9 | YANG Q , WU X D . 10 challenging problems in data mining research[J]. International Journal of Information Technology & Decision Making, 2006, 5 (4): 597- 604. |
| 10 | SMYTH P . Clustering sequences with hidden markov models[J]. NIPS, 1997, 9: 648- 654. |
| 11 | OREBAUGH A , RAMIREZ G , BURKE J , et al. Wireshark & Ethereal network protocol analyzer toolkit[M]. Cambridge: Elsevier, 2007. |
| 12 | JOHNSON L . Weavings Women Doing Theology in Oceania[M]. Fiji: Wcavers, 2003. |
| 13 |
王维彬, 钟润添. 一种基于贪心EM算法学习GMM的聚类算法[J]. 计算机仿真, 2007, 24 (2): 65- 68.
doi: 10.3969/j.issn.1006-9348.2007.02.018 |
|
WANG Weibin , ZHONG Runtian . A clustering algorithm based on greedy EM algorithm learning GMM[J]. Computer Simulation, 2007, 24 (2): 65- 68.
doi: 10.3969/j.issn.1006-9348.2007.02.018 |
|
| 14 | ESTER M, KRIEGEL HP, XU X. A density-based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise[C]//International Conference on Knowledge Discovery and Data Mining. Palo Alto: AAAI Press, 1996: 226-231. |
| 15 |
BAI L , CHENG X Q , LIANG J Y , et al. Fast density clustering strategies based on the K-means algorithm[J]. Pattern Recognition, 2017, 71: 375- 386.
doi: 10.1016/j.patcog.2017.06.023 |
| 16 |
TÎRNĂUCĂ C , GÓMEZ-PÉREZ D , BALCÁZAR J L , et al. Global optimality in k-means clustering[J]. Information Sciences, 2018, 439/440: 79- 94.
doi: 10.1016/j.ins.2018.02.001 |
| 17 |
NAZNIN F , SARKER R , ESSAM D . Progressive alignment method using genetic algorithm for multiple sequence alignment[J]. IEEE Transactions on Evolutionary Computation, 2012, 16 (5): 615- 631.
doi: 10.1109/TEVC.2011.2162849 |
| 18 | LEE C T , PENG S L . A pairwise alignment algorithm for long sequences of high similarity[M]. Singapore: Springer, 2017: 279- 287. |
| 19 | WIDE MAWI Working Group[EB/OL].[2018-5-20]. http://mawi.wide.ad.jp/. |
| [1] | 刘国涛,张燕平,徐晨初. 一种优化覆盖中心的三支决策模型[J]. 山东大学学报(理学版), 2017, 52(3): 105-110. |
| [2] | 及歆荣,侯翠琴,侯义斌,赵斌. 基于筛选机制的L1核学习机分布式训练方法[J]. 山东大学学报(理学版), 2016, 51(9): 137-144. |
| [3] | 吴修国 曾广周. 目标描述逻辑研究[J]. J4, 2009, 44(11): 68-74. |
| [4] | 许传轲 陈月辉 赵亚欧. 基于改进伪氨基酸组成的蛋白质相互作用预测[J]. J4, 2009, 44(9): 17-21. |
| [5] | 修明 陈保会 史开泉. F-粗规律与它的属性控制[J]. J4, 2008, 43(12): 66-72. |
| [6] | 张 凌,邱育锋,任雪芳, . 基于单向S-粗集的知识堆垒与知识垛识别[J]. J4, 2008, 43(10): 12-17 . |
| [7] | 付海艳,卢昌荆,史开泉 . (F,F-)-规律推理与规律挖掘[J]. J4, 2007, 42(7): 54-57 . |
| [8] | 张 凌,邱育峰,任雪芳 . 粗规律生成与它的分离[J]. J4, 2008, 43(3): 58-63 . |
| [9] | 付海艳,史开泉 . 知识过滤与属性f-迁移依赖[J]. J4, 2007, 42(10): 54-58 . |
| [10] | 翟俊海, 张垚, 王熙照. 相容粗糙模糊集模型[J]. 山东大学学报(理学版), 2014, 49(08): 73-79. |
| [11] | 张聪, 于洪. 一种三支决策软增量聚类算法[J]. 山东大学学报(理学版), 2014, 49(08): 40-47. |
|