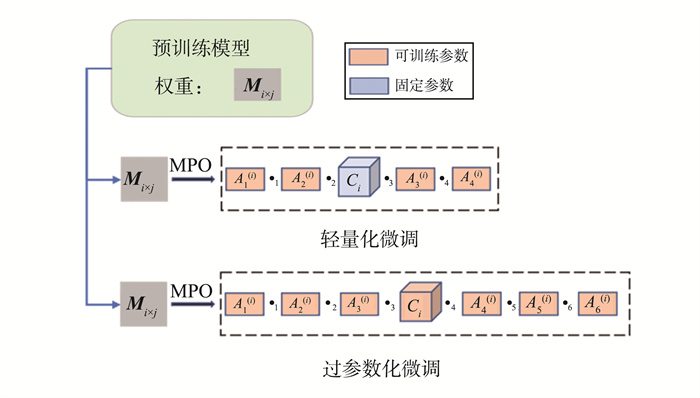
JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE) ›› 2024, Vol. 59 ›› Issue (7): 44-52, 104.doi: 10.6040/j.issn.1671-9352.1.2023.042
• Review • Previous Articles Next Articles
Peiyu LIU1( ),Bowen YAO2,Zefeng GAO1,2,*(),Wayne Xin ZHAO1,*()
),Bowen YAO2,Zefeng GAO1,2,*(),Wayne Xin ZHAO1,*()
CLC Number:
| 1 | LI Jing, REN Pengjie, CHEN Zhumin, et al. Neural attentive session-based recommendation[EB/OL]. (2017-11-13)[2023-08-09]. http://arxiv.org/abs/1711.04725. |
| 2 | HOU Yupeng, HU Binbin, ZHANG Zhiqiang, et al. CORE: simple and effective session-based recommendation within consistent representation space[C]//SIGIR'22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: Association for Computing Machinery, 2022: 1796-1801. |
| 3 | HOU Y, MU S, ZHAO W X, et al. Towards universal sequence representation learning for recommender systems[EB/OL]. (2022-06-13)[2023-04-13]. http://arxiv.org/abs/2206.05941. |
| 4 | XU Ruixin, LUO Fuli, ZHANG Zhiyuan, et al. Raise a child in large language model: towards effective and generalizable fine-tuning[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: Association for Computational Linguistics, 2021: 9514-9528. |
| 5 | HIDASI B, KARATZOGLOU A, BALTRUNAS L, et al. Session-based recommendations with recurrent neural networks[C/OL]//4th International Conference on Learning Representations (ICLR 2016). 2016: 1-10. http://arxiv.org/pdf/1511.06939. |
| 6 | ZHOU K H, YU H, ZHAO W X, et al. Filter-enhanced MLP is all you need for sequential recommendation[C]//WWW̓22: The ACM Web Conference 2022. Lyon: ACM, 2022: 2388-2399. |
| 7 | CHANG Jianxin, GAO Chen, ZHENG Yu, et al. Sequential recommendation with graph neural networks[EB/OL]. (2023-07-26)[2023-08-09]. http://arxiv.org/abs/2106.14226. |
| 8 | YUAN F, HE X, KARATZOGLOU A, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2020. New York: ACM, 2020: 1469-1478. |
| 9 | GAO Zefeng, ZHOU Kun, LIU Peiyu, et al. Small pre-trained language models can be fine-tuned as large models via over-parameterization[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ACL 2023. Toronto: Association for Computational Linguistics, 2023: 3819-3834. |
| 10 | GAO Zefeng , CHENG Song , HE Rongqiang , et al. Compressing deep neural networks by matrix product operators[J]. Physical Review Research, 2020, 2 (2): 023300. |
| 11 | GAO Zefeng, SUN Xingwei, GAO Lan, et al. Compressing LSTM networks by matrix product operators[EB/OL]. (2022-03-31)[2023-05-06]. https://arxiv.org/abs/2012.11943. |
| 12 | NOVIKOV A, PODOPRIKHIN D, OSOKIN A, et al. Tensorizing neural networks[EB/OL]. (2015-09-22)[2023-05-06]. https://arxiv.org/abs/1509.06569. |
| 13 | GARIPOV T, PODOPRIKHIN D, NOVIKOV A, et al. Ultimate tensorization: compressing convolutional and FC layers alike[EB/OL]. (2016-11-10)[2023-05-06]. https://arxiv.org/abs/1611.03214. |
| 14 | LIU P, GAO Z F, ZHAO W X, et al. Enabling lightweight fine-tuning for pre-trained language model compression based on matrix product operators[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: Association for lomputational Linguistics, 2021: 5388-5398. |
| 15 | GAO Z F, LIU P, ZHAO W X, et al. Parameter-efficient mixture-of-experts architecture for pre-trained language models[C]//Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju: International Committee on Computational Linguistics, 2022: 3263-3273. |
| 16 | LIU Peiyu, GAO Zefeng, CHEN Yushuo, et al. Scaling pre-trained language models to deeper via parameter-efficient architecture[EB/OL]. (2023-04-10)[2023-05-06]. http://arxiv.org/abs/2303.16753. |
| 17 | SUN Xingwei , GAO Zefeng , LU Zhengyi , et al. A model compression method with matrix product operators for speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28, 2837- 2847. |
| 18 | EDWARD J H, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. (2021-10-16)[2022-06-16]. http://arxiv.org/abs/2106.09685. |
| 19 | NI J, LI J, MCAULEY J J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 188-197. |
| 20 | ZHOU K, WANG H, ZHAO W X, et al. S3Rec: self-supervised learning for sequential recommendation with mutual information maximization[C/OL]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. [2023-08-08]. https://doi.org/10.1145/3340531.3411954. |
| 21 | SUN Fei, LIU Jun, WU Jian, et al. BERT4Rec: sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing: ACM, 2019: 1441-1450. |
| 22 | WEN Keyu, TAN Zhenshan, CHENG Qingrong, et al. Contrastive cross-modal knowledge sharing pre-training for vision-language representation learning and retrieval[EB/OL]. (2022-07-08)[2023-10-18]. http://arxiv.org/abs/2207.00733. |
| [1] | GU Feng,LIU Chen-xi,WU Yangyang . Chinese Web page feature selection method based on Sequential data mining [J]. J4, 2006, 41(3): 95-99 . |
|