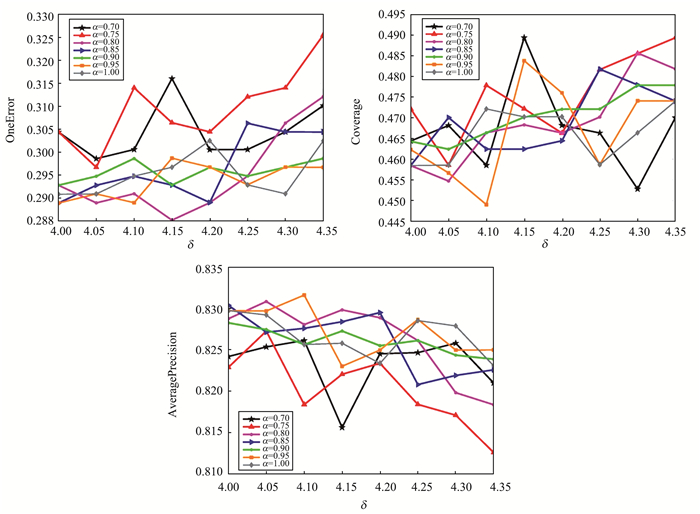
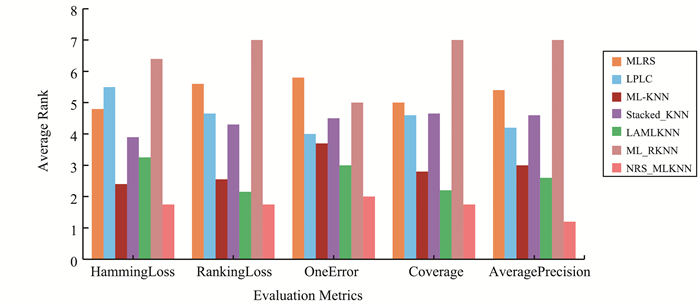
JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE) ›› 2024, Vol. 59 ›› Issue (3): 107-117.doi: 10.6040/j.issn.1671-9352.2.2023.027
Previous Articles Next Articles
Xin WEN1( ),Deyu LI1,2,*()
),Deyu LI1,2,*()
CLC Number:
| 1 |
YU Ying , PEDRYCZ W , MIAO Duoqian . Multi-label classification by exploiting label correlations[J]. Expert Systems with Applications, 2014, 41 (6): 2989- 3004.
doi: 10.1016/j.eswa.2013.10.030 |
| 2 |
TSOUMAKAS G , KATAKIS I . Multi-label classification: an overview[J]. International Journal of Data Warehousing and Mining, 2007, 3 (3): 1- 13.
doi: 10.4018/jdwm.2007070101 |
| 3 |
ZHANG Minling , ZHOU Zhihua . A review on multi-label learning algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26 (8): 1819- 1837.
doi: 10.1109/TKDE.2013.39 |
| 4 |
KASHEF S , NEZAMABADI-POUR H . A label-specific multi-label feature selection algorithm based on the Pareto dominance concept[J]. Pattern Recognition, 2019, 88, 654- 667.
doi: 10.1016/j.patcog.2018.12.020 |
| 5 |
LEE J , SEO W , PARK J H , et al. Compact feature subset-based multi-label music categorization for mobile devices[J]. Multimedia Tools and Applications, 2019, 78 (4): 4869- 4883.
doi: 10.1007/s11042-018-6100-8 |
| 6 |
WANG R , RIDLEY R , SU X A , et al. A novel reasoning mechanism for multi-label text classification[J]. Information Processing and Management, 2021, 58 (2): 102441.
doi: 10.1016/j.ipm.2020.102441 |
| 7 | FABRIS F, FREITAS A A. Dependency network methods for hierarchical multi-label classification of gene functions[C]//2014 IEEE Symposium on Computational Intelligence and Data Mining. Piscataway: IEEE, 2014: 241-248. |
| 8 | AKHAND B, DEVI V S. Multi-label classification of discrete data[C]//IEEE International Conference on Fuzzy Systems. Piscataway: IEEE, 2013: 1-5. |
| 9 |
BOUTELL M R , LUO J B , SHEN X P , et al. Learning multi-label scene classification[J]. Pattern Recognition, 2004, 37 (9): 1757- 1771.
doi: 10.1016/j.patcog.2004.03.009 |
| 10 |
TSOUMAKAS G , KATAKIS I , VLAHAVAS I P . Random k-labelsets for multilabel classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 23 (7): 1079- 1089.
doi: 10.1109/TKDE.2010.164 |
| 11 | READ J, PFAHRINGER B, HOLMES G, et al. Classifier chains for multi-label classification[C]//Machine Learning and Knowledge Discovery in Databases. European Conference, Berlin: Springer, 2009, 5782: 254-269. |
| 12 |
ZHANG Minling , ZHOU Zhihua . ML-kNN: a lazy learning approach to multi-label learning[J]. Pattern Recognition, 2007, 40 (7): 2038- 2048.
doi: 10.1016/j.patcog.2006.12.019 |
| 13 | PAKRASHI A, NAMEE B M. Stacked-MLkNN: a stacking based improvement to multi-label k-nearest neighbours[C]//First International Workshop on Learning with Imbalanced Domains: Theory and Applications. New York: PMLR, 2017, 74: 51-63. |
| 14 | WANG Dengbao, WANG Jingyuan, HU Fei, et al. A locally adaptive multi-label k-nearest neighbor algorithm[C]//Advances in Knowledge Discovery and Data Mining-22nd Pacific-Asia Conference. Berlin: Springer, 2018, 10937: 81-93. |
| 15 | SADHUKHAN P, PALIT S. Multi-label learning on principles of reverse k-nearest neighbourhood[J/OL]. Expert Systems, 2020. DOI: 10.1111/exsy.12615. |
| 16 | 段洁, 胡清华, 张灵均, 等. 基于邻域粗糙集的多标记分类特征选择算法[J]. 计算机研究与发展, 2015, 52 (1): 56- 65. |
| DUAN Jie , HU Qinghua , ZHANG Lingjun , et al. Feature selection for multi-label classification based on neighborhood rough sets[J]. Journal of Computer Research and Development, 2015, 52 (1): 56- 65. | |
| 17 | 张文修, 吴伟志, 梁吉业, 等. 粗糙集理论与方法[M]. 北京: 科学出版社, 2001: 232. |
| ZHANG Wenxiu , WU Weizhi , LIANG Jiye , et al. Rough sets theory and methods[M]. Beijing: Science Press, 2001: 232. | |
| 18 |
HU Qinghua , YU Daren , LIU Jinfu , et al. Neighborhood rough set based heterogeneous feature subset selection[J]. Information Sciences, 2008, 178 (18): 3577- 3594.
doi: 10.1016/j.ins.2008.05.024 |
| 19 | 张晶, 李德玉, 王素格, 等. 基于稳健模糊粗糙集模型的多标记文本分类[J]. 计算机科学, 2015, 42 (7): 270- 275. |
| ZHANG Jing , LI Deyu , WANG Suge , et al. Multi-label text classification based on robust fuzzy rough set model[J]. Journal of Computer Science, 2015, 42 (7): 270- 275. | |
| 20 |
DAI Jianhua , HU Hu , WU Weizhi , et al. Maximal-discernibility-pair-based approach to attribute reduction in fuzzy rough sets[J]. IEEE Transactions on Fuzzy Systems, 2018, 26 (4): 2174- 2187.
doi: 10.1109/TFUZZ.2017.2768044 |
| 21 |
QIAN Wenbin , HUANG Jintao , WANG Yinglong , et al. Label distribution feature selection for multi-label classification with rough set[J]. International Journal of Approximate Reasoning, 2021, 128, 32- 55.
doi: 10.1016/j.ijar.2020.10.002 |
| 22 | 温欣, 李德玉, 王素格. 一种基于邻域关系和模糊决策的特征选择方法[J]. 南京大学学报(自然科学版), 2018, 54 (4): 733- 741. |
| WEN Xin , LI Deyu , WANG Suge . A method for feature selection based on neighborhood relation and fuzzy decision[J]. Journal of Nanjing University (Natural Sciences), 2018, 54 (4): 733- 741. | |
| 23 |
HUANG Jun , LI Guorong , WANG Shuhui , et al. Multi-label classification by exploiting local positive and negative pairwise label correlation[J]. Neurocomputing, 2017, 257, 164- 174.
doi: 10.1016/j.neucom.2016.12.073 |
| [1] | Chengxiang HU,Li ZHANG,Xiaoling HUANG,Huibin WANG. Dynamic neighborhood rough sets approaches for updating knowledge while attributes generalization [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2023, 58(7): 37-51. |
| [2] | SHI Junpeng, ZHANG Yanlan. Dynamic updating algorithm of local neighborhood rough sets with the deletion of objects [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2023, 58(5): 17-25. |
| [3] | LIU Changshun, LIU Yan, SONG Jingjing, XU Taihua. Attribute reduction algorithm based on discreteness of the universe [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2023, 58(5): 26-35. |
| [4] | ZHENG Cheng-yu, WANG Xin, WANG Ting, DENG Ya-ping, YIN Tian-tian. Multi-label classification for medical text based on ALBERT-TextCNN model [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2022, 57(4): 21-29. |
| [5] | SUN Lin, LIANG Na, XU Jiu-cheng. Feature selection using adaptive neighborhood mutual information and spectral clustering [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2022, 57(12): 13-24. |
|