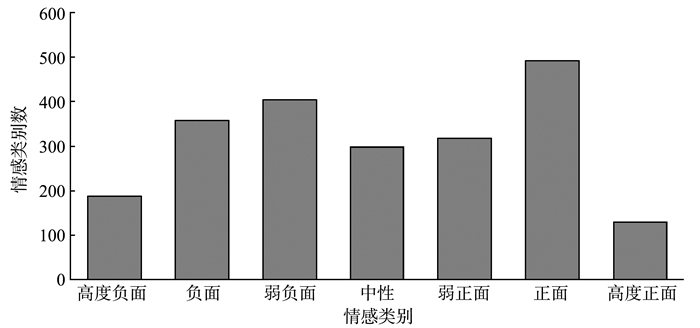
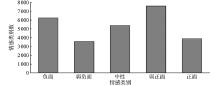
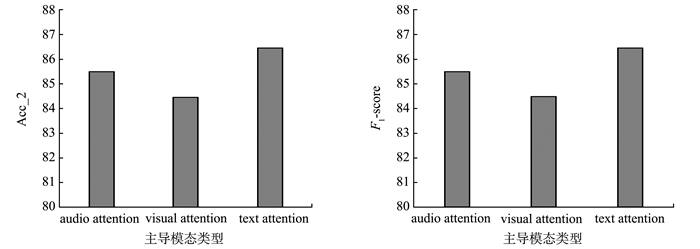
JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE) ›› 2023, Vol. 58 ›› Issue (12): 31-40, 51.doi: 10.6040/j.issn.1671-9352.1.2022.421
Previous Articles Next Articles
Chan LU1,2( ),Junjun GUO1,2,*(),Kaiwen TAN1,2,Yan XIANG1,2,Zhengtao YU1,2
),Junjun GUO1,2,*(),Kaiwen TAN1,2,Yan XIANG1,2,Zhengtao YU1,2
CLC Number:
| 1 | JIMING L I U , PEIXIANG Z , YING L I U , et al.Summary of multi-modal sentiment analysis technology[J].Journal of Frontiers of Computer Science & Technology,2021,15(7):1165. |
| 2 | SUN Z, SARMA P, SETHARES W, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020: 8992-8999. |
| 3 | ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1103-1114. |
| 4 | ZADEH A, LIANG P P, MAZUMDER N, et al. Memory fusion network for multi-view sequential learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New Orleans: AAAI Press, 2018: 5634-5641. |
| 5 | TSAI Y H H, BAI S, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: Association for Computational Linguistics, 2019: 6558-6569. |
| 6 | YU W, XU H, YUAN Z, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 10790-10797. |
| 7 | WILLIAMS J, KLEINEGESSE S, COMANESCU R, et al. Recognizing emotions in video using multimodal DNN feature fusion[C]//Proceedings of Grand Challenge and Workshop on Human Multimodal Language. Melbourne: Association for Computational Linguistics, 2018: 11-19. |
| 8 | LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: Association for Computational Linguistics, 2018: 2247-2256. |
| 9 | MAI S, HU H, XING S. Modality to modality translation: an adversarial representation learning and graph fusion network for multimodal fusion[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 164-172. |
| 10 | ZHOU S, JIA J, YIN Y, et al. Understanding the teaching styles by an attention based multi-task cross-media dimensional modeling[C]//Proceedings of the 27th ACM International Conference on Multimedia. New York: Association for Computing Machinery, 2019: 1322-1330. |
| 11 | CHEN M, LI X. Swafn: sentimental words aware fusion network for multimodal sentiment analysis[C]//Proceedings of the 28th International Conference on Computational Linguistics. Barcelona: International Committee on Computational Linguistics, 2020: 1067-1077. |
| 12 | HAN W, CHEN H, PORIA S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: Association for Computational Linguistics, 2021: 9180-9192. |
| 13 | PHAM H, LIANG P P, MANZINI T, et al. Found in translation: learning robust joint representations by cyclic translations between modalities[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI Press, 2019: 6892-6899. |
| 14 | VASWANI A , SHAZEER N , PARMAR N , et al.Attention is all you need[J].Advances in Neural Information Processing Systems,2017,30,5998-6008. |
| 15 | HAZARIKA D, ZIMMERMANN R, PORIA S. Misa: modality-invariant and specific representations for multimodal sentiment analysis[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: Association for Computing Machinery, 2020: 1122-1131. |
| 16 | WANG Y, SHEN Y, LIU Z, et al. Words can shift: dynamically adjusting word representations using nonverbal behaviors[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: AAAI Press, 2019: 7216-7223. |
| 17 | RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained transformers[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2020: 2359-2369. |
| 18 | ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis[C]//International Conference on Machine Learning. Atlanta: JMLR. org, 2013: 1247-1255. |
| 19 | DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Minneapolis: Association for Computational Linguistics, 2019: 4171-4186. |
| 20 |
HOCHREITER S , SCHMIDHUBER J .Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
doi: 10.1162/neco.1997.9.8.1735 |
| 21 | ZADEH A , ZELLERS R , PINCUS E , et al.MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[J].IEEE Intelligent Systems,2016,82-88. |
| 22 | ZADEH A, PU P. Multimodal language analysis in the wild: cmu-mosei dataset and interpretable dynamic fusion graph[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers). Melbourne: Association for Computational Linguistics, 2018: 2236-2246. |
| [1] | Yujia NA,Jun XIE,Haiyang YANG,Xinying XU. Context fusion-based knowledge graph completion [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2023, 58(9): 71-80. |
| [2] | WANG Jing-hong, LIANG Li-na, LI Hao-kang, WANG Xi-zhao. Community discovery algorithm based on label attention mechanism [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2022, 57(12): 1-12. |
| [3] | BAO Liang, CHEN Zhi-hao, CHEN Wen-zhang, YE Kai, LIAO Xiang-wen. Dual co-matching network with multiway attention for opinion reading comprehension [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2021, 56(3): 44-53. |
| [4] | TANG Guang-yuan, GUO Jun-jun, YU Zheng-tao, ZHANG Ya-fei,GAO Sheng-xiang. Method of recommendation based on knowledge driven by BERT and law [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2021, 56(11): 24-30. |
| [5] | Chang-ying HAO,Yan-yan LAN,Hai-nan ZHANG,Jia-feng GUO,Jun XU,Liang PANG,Xue-qi CHENG. Dialogue generation model based on extended keywords information [J]. JOURNAL OF SHANDONG UNIVERSITY(NATURAL SCIENCE), 2019, 54(7): 68-76. |