《山东大学学报(理学版)》 ›› 2024, Vol. 59 ›› Issue (7): 44-52, 104.doi: 10.6040/j.issn.1671-9352.1.2023.042
刘沛羽1( ),姚博文2,高泽峰1,2,*(),赵鑫1,*()
),姚博文2,高泽峰1,2,*(),赵鑫1,*()
Peiyu LIU1(),Bowen YAO2,Zefeng GAO1,2,*(),Wayne Xin ZHAO1,*()
摘要:
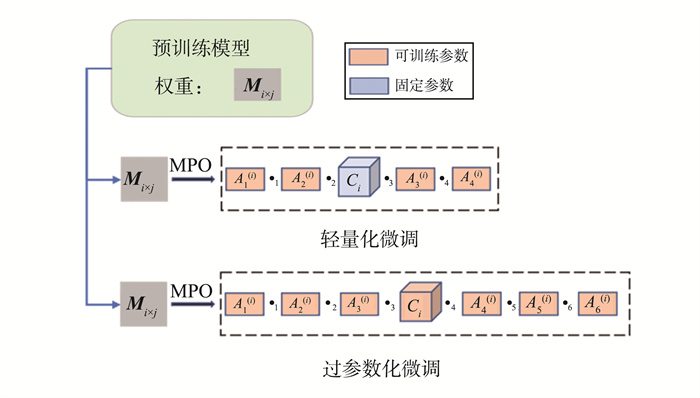
推荐系统中的序列化推荐任务面临着高度复杂和多样性大的挑战, 基于序列化数据的商品表示学习中广泛采用预训练和微调的方法,现有方法通常忽略了在新领域中模型微调可能会遇到的欠拟合和过拟合问题。为了应对这一问题,构建一种基于矩阵乘积算符(matrix product operator, MPO)表示的神经网络结构,并实现2种灵活的微调策略。首先,通过仅更新部分参数的轻量化微调策略,有效地缓解微调过程中的过拟合问题;其次,通过增加可微调参数的过参数化微调策略,有力地应对微调中的欠拟合问题。经过实验验证,该方法在现有开源数据集上均实现显著的性能提升,充分展示在实现通用的物品表示问题上的有效性。
中图分类号:
| 1 | LI Jing, REN Pengjie, CHEN Zhumin, et al. Neural attentive session-based recommendation[EB/OL]. (2017-11-13)[2023-08-09]. http://arxiv.org/abs/1711.04725. |
| 2 | HOU Yupeng, HU Binbin, ZHANG Zhiqiang, et al. CORE: simple and effective session-based recommendation within consistent representation space[C]//SIGIR'22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: Association for Computing Machinery, 2022: 1796-1801. |
| 3 | HOU Y, MU S, ZHAO W X, et al. Towards universal sequence representation learning for recommender systems[EB/OL]. (2022-06-13)[2023-04-13]. http://arxiv.org/abs/2206.05941. |
| 4 | XU Ruixin, LUO Fuli, ZHANG Zhiyuan, et al. Raise a child in large language model: towards effective and generalizable fine-tuning[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: Association for Computational Linguistics, 2021: 9514-9528. |
| 5 | HIDASI B, KARATZOGLOU A, BALTRUNAS L, et al. Session-based recommendations with recurrent neural networks[C/OL]//4th International Conference on Learning Representations (ICLR 2016). 2016: 1-10. http://arxiv.org/pdf/1511.06939. |
| 6 | ZHOU K H, YU H, ZHAO W X, et al. Filter-enhanced MLP is all you need for sequential recommendation[C]//WWW̓22: The ACM Web Conference 2022. Lyon: ACM, 2022: 2388-2399. |
| 7 | CHANG Jianxin, GAO Chen, ZHENG Yu, et al. Sequential recommendation with graph neural networks[EB/OL]. (2023-07-26)[2023-08-09]. http://arxiv.org/abs/2106.14226. |
| 8 | YUAN F, HE X, KARATZOGLOU A, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2020. New York: ACM, 2020: 1469-1478. |
| 9 | GAO Zefeng, ZHOU Kun, LIU Peiyu, et al. Small pre-trained language models can be fine-tuned as large models via over-parameterization[C]//Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ACL 2023. Toronto: Association for Computational Linguistics, 2023: 3819-3834. |
| 10 | GAO Zefeng , CHENG Song , HE Rongqiang , et al. Compressing deep neural networks by matrix product operators[J]. Physical Review Research, 2020, 2 (2): 023300. |
| 11 | GAO Zefeng, SUN Xingwei, GAO Lan, et al. Compressing LSTM networks by matrix product operators[EB/OL]. (2022-03-31)[2023-05-06]. https://arxiv.org/abs/2012.11943. |
| 12 | NOVIKOV A, PODOPRIKHIN D, OSOKIN A, et al. Tensorizing neural networks[EB/OL]. (2015-09-22)[2023-05-06]. https://arxiv.org/abs/1509.06569. |
| 13 | GARIPOV T, PODOPRIKHIN D, NOVIKOV A, et al. Ultimate tensorization: compressing convolutional and FC layers alike[EB/OL]. (2016-11-10)[2023-05-06]. https://arxiv.org/abs/1611.03214. |
| 14 | LIU P, GAO Z F, ZHAO W X, et al. Enabling lightweight fine-tuning for pre-trained language model compression based on matrix product operators[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg: Association for lomputational Linguistics, 2021: 5388-5398. |
| 15 | GAO Z F, LIU P, ZHAO W X, et al. Parameter-efficient mixture-of-experts architecture for pre-trained language models[C]//Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju: International Committee on Computational Linguistics, 2022: 3263-3273. |
| 16 | LIU Peiyu, GAO Zefeng, CHEN Yushuo, et al. Scaling pre-trained language models to deeper via parameter-efficient architecture[EB/OL]. (2023-04-10)[2023-05-06]. http://arxiv.org/abs/2303.16753. |
| 17 | SUN Xingwei , GAO Zefeng , LU Zhengyi , et al. A model compression method with matrix product operators for speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28, 2837- 2847. |
| 18 | EDWARD J H, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[EB/OL]. (2021-10-16)[2022-06-16]. http://arxiv.org/abs/2106.09685. |
| 19 | NI J, LI J, MCAULEY J J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong: Association for Computational Linguistics, 2019: 188-197. |
| 20 | ZHOU K, WANG H, ZHAO W X, et al. S3Rec: self-supervised learning for sequential recommendation with mutual information maximization[C/OL]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. [2023-08-08]. https://doi.org/10.1145/3340531.3411954. |
| 21 | SUN Fei, LIU Jun, WU Jian, et al. BERT4Rec: sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing: ACM, 2019: 1441-1450. |
| 22 | WEN Keyu, TAN Zhenshan, CHENG Qingrong, et al. Contrastive cross-modal knowledge sharing pre-training for vision-language representation learning and retrieval[EB/OL]. (2022-07-08)[2023-10-18]. http://arxiv.org/abs/2207.00733. |
| [1] | 张晓媛, 田毅, 任子涵, 段天宇, 杨斯媛, 张月轩. 拓扑邻域基在密度聚类算法中的应用[J]. 《山东大学学报(理学版)》, 2026, 61(5): 55-64. |
| [2] | 孙迪,郭义童,任超,范海峰,张传雷. 基于多尺度特征融合与改进注意力的锈蚀螺栓螺帽检测[J]. 《山东大学学报(理学版)》, 2026, 61(1): 1-14. |
| [3] | 仲尚,马丽,刘文哲,李雨豪. 融合多尺度注意力机制和改进特征融合的轻量化水面小目标检测模型[J]. 《山东大学学报(理学版)》, 2026, 61(1): 15-25. |
| [4] | 余雷,孙懿,华金铭,李腊全. 基于深度神经网络的重症监护室脓毒症患者死亡风险预测模型分析[J]. 《山东大学学报(理学版)》, 2026, 61(1): 26-35. |
| [5] | 王军涛,黄强. 基于一般重叠函数的模糊数学形态学边缘检测方法[J]. 《山东大学学报(理学版)》, 2026, 61(1): 36-48. |
| [6] | 李文焱,李丽红,王洪欣. 基于知识度量的模糊粗糙c-均值算法[J]. 《山东大学学报(理学版)》, 2026, 61(1): 49-64. |
| [7] | 孙清,叶军,曾广财,宋苏洋,汪一心. 结合蝙蝠算法和紧密度改进的三支K-means算法[J]. 《山东大学学报(理学版)》, 2026, 61(1): 65-75. |
| [8] | 邹峥,雷雨晟,刘石坚,王定一,邱学炜,史雯雯,周校通. 白蚁分区式微方向感知的精确形态识别[J]. 《山东大学学报(理学版)》, 2026, 61(1): 76-84. |
| [9] | 梁霞,郭洁. 基于在线评论的线上教学平台选择方法[J]. 《山东大学学报(理学版)》, 2024, 59(9): 108-118. |
| [10] | 黎超,廖薇. 基于医疗知识驱动的中文疾病文本分类模型[J]. 《山东大学学报(理学版)》, 2024, 59(7): 122-130. |
| [11] | 纪杰,孙承杰,单丽莉,尚伯乐,林磊. 基于提示学习的电信网络诈骗案件分类方法[J]. 《山东大学学报(理学版)》, 2024, 59(7): 113-121. |
| [12] | 罗奇,苟刚. 基于聚类和群组归一化的多模态对话情绪识别[J]. 《山东大学学报(理学版)》, 2024, 59(7): 105-112. |
| [13] | 赵峰叙,王健,林原,林鸿飞. 面向排序学习的概率分布优化模型[J]. 《山东大学学报(理学版)》, 2024, 59(7): 95-104. |
| [14] | 黄兴宇,赵明宇,吕子钰. 面向图神经网络表征学习的类别知识探针[J]. 《山东大学学报(理学版)》, 2024, 59(7): 85-94. |
| [15] | 桂梁,徐遥,何世柱,张元哲,刘康,赵军. 基于动态邻居选择的知识图谱事实错误检测方法[J]. 《山东大学学报(理学版)》, 2024, 59(7): 76-84. |
|
||