《山东大学学报(理学版)》 ›› 2024, Vol. 59 ›› Issue (1): 46-55,71.doi: 10.6040/j.issn.1671-9352.0.2022.623
罗兴隆1( ),贺兴时1,*(),周洁1,杨新社2
),贺兴时1,*(),周洁1,杨新社2
Xinglong LUO1(),Xingshi HE1,*(),Jie ZHOU1,Xinshe YANG2
摘要:
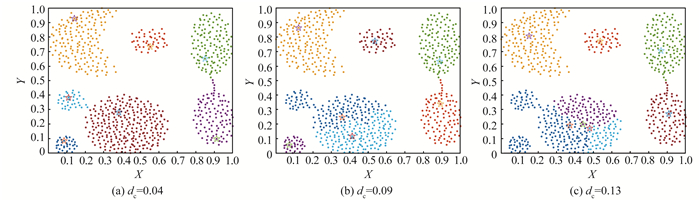
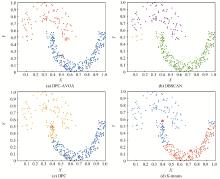
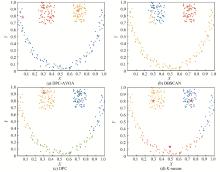
密度峰值聚类算法是一种自动寻找簇中心的新型快速搜索算法。针对其截断距离的不确定和一步式分配策略不稳健等缺陷, 本文提出一种基于非洲秃鹫优化算法改进的密度峰值聚类算法。通过准确率(accuracy, Acc)这一评价指标建立优化问题的目标函数, 利用非洲秃鹫优化算法强大的寻优能力对不确定的截断距离dc进行优化, 降低了人为取值的不准确性; 其次, 根据数据集密度均值将其划分为高低不同的密度区域, 对不同区域采用不同的分配策略, 针对高密度区域内的数据点采用与原密度峰值聚类相同的分配方法, 对低密度区域内数据点则根据其k近邻数量进行聚类; 最后, 将该算法在合成和真实数据集上进行实验验证, 算法的聚类性能有了很大的提升, 且对密度差异性较大的数据集划分也更加精确。
中图分类号:
| 1 |
STREHL A , GHOSH J . Relationship-based clustering and visualization for high-dimensional data mining[J]. INFORMS Journal on Computing, 2003, 15 (2): 208- 230.
doi: 10.1287/ijoc.15.2.208.14448 |
| 2 |
DONG Gaogao , TIAN Lixin , DU Ruijin , et al. Analysis of percolation behaviors of clustered networks with partial support-dependence relations[J]. Physica A: Statistical Mechanics and its Applications, 2014, 394, 370- 378.
doi: 10.1016/j.physa.2013.09.055 |
| 3 |
RODRIGUEZ A , LAIO A . Clustering by fast search and find of density peaks[J]. Science, 2014, 344 (6191): 1492- 1496.
doi: 10.1126/science.1242072 |
| 4 |
CHEN Yewang , LAI Dehe , QI Han , et al. A new method to estimate ages of facial image for large database[J]. Multimedia Tools and Applications, 2016, 75 (5): 2877- 2895.
doi: 10.1007/s11042-015-2485-9 |
| 5 |
XIE Juanying , GAO Hongchao , XIE Weixin , et al. Robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors[J]. Information Sciences, 2016, 354, 19- 40.
doi: 10.1016/j.ins.2016.03.011 |
| 6 |
MEHMOOD R , ZHANG Guangzhi , BIE Rongfang , et al. Clustering by fast search and find of density peaks via heat diffusion[J]. Neurocomputing, 2016, 208, 210- 217.
doi: 10.1016/j.neucom.2016.01.102 |
| 7 | TANG Guihua, JIA Sen, LI Jun. An enhanced density peak-based clustering approach for hyperspectral band selection[C]//2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). New York: IEEE, 2015: 1116-1119. |
| 8 |
WANG Shuliang , WANG Dakui , LI Caoyuan , et al. Clustering by fast search and find of density peaks with data field[J]. Chinese Journal of Electronics, 2016, 25 (3): 397- 402.
doi: 10.1049/cje.2016.05.001 |
| 9 |
JIANG Dong , ZANG Wenke , SUN Rui , et al. Adaptive density peaks clustering based on K-nearest neighbor and Gini coefficient[J]. IEEE Access, 2020, 8, 113900- 113917.
doi: 10.1109/ACCESS.2020.3003057 |
| 10 |
DU Mingjing , DING Shifei , XU Xiao , et al. Density peaks clustering using geodesic distances[J]. International Journal of Machine Learning and Cybernetics, 2018, 9 (8): 1335- 1349.
doi: 10.1007/s13042-017-0648-x |
| 11 |
WANG Xiaofeng , XU Yifan . Fast clustering using adaptive density peak detection[J]. Statistical Methods in Medical Research, 2017, 26 (6): 2800- 2811.
doi: 10.1177/0962280215609948 |
| 12 |
DU Mingjing , DING Shifei , JIA Hongjie . Study on density peaks clustering based on k-nearest neighbors and principal component analysis[J]. Knowledge-Based Systems, 2016, 99, 135- 145.
doi: 10.1016/j.knosys.2016.02.001 |
| 13 | 丁志成, 葛洪伟, 周竞. 基于KL散度的密度峰值聚类算法[J]. 重庆邮电大学学报(自然科学版), 2019, 31 (3): 367- 374. |
| DING Zhicheng , GE Hongwei , ZHOU Jing . Density peaks clustering based on Kullback Leibler divergence[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2019, 31 (3): 367- 374. | |
| 14 | 谢娟英, 高红超, 谢维信. K近邻优化的密度峰值快速搜索聚类算法[J]. 中国科学(信息科学), 2016, 46 (2): 258- 280. |
| XIE Juanying , GAO Hongchao , XIE Weixin . K-nearest neighbors optimized clustering algorithm by fast search and finding the density peaks of a dataset[J]. Science China(Information Science), 2016, 46 (2): 258- 280. | |
| 15 |
YU Donghua , LIU Guojun , GUO Maozu , et al. Density peaks clustering based on weighted local density sequence and nearest neighbor assignment[J]. IEEE Access, 2019, 7, 34301- 34317.
doi: 10.1109/ACCESS.2019.2904254 |
| 16 |
SEYEDI S A , LOTFI A , MORADI P , et al. Dynamic graph-based label propagation for density peaks clustering[J]. Expert Systems with Applications, 2019, 115, 314- 328.
doi: 10.1016/j.eswa.2018.07.075 |
| 17 |
LIU Rui , WANG Hong , YU Xiaomei . Shared-nearest-neighbor-based clustering by fast search and find of density peaks[J]. Information Sciences, 2018, 450, 200- 226.
doi: 10.1016/j.ins.2018.03.031 |
| 18 |
LÜ Yi , LIU Mandan , XIANG Yue . Fast searching density peak clustering algorithm based on shared nearest neighbor and adaptive clustering center[J]. Symmetry, 2020, 12 (12): 2014.
doi: 10.3390/sym12122014 |
| 19 |
LIU Yaohui , MA Zhengming , YU Fang . Adaptive density peak clustering based on K-nearest neighbors with aggregating strategy[J]. Knowledge-based Systems, 2017, 133, 208- 220.
doi: 10.1016/j.knosys.2017.07.010 |
| 20 |
HOU Jian , ZHANG Aihua , QI Naiming . Density peak clustering based on relative density relationship[J]. Pattern Recognition, 2020, 108, 107554.
doi: 10.1016/j.patcog.2020.107554 |
| 21 |
WANG Yizhang , WANG Di , ZHANG Xiaofeng , et al. McDPC: multi-center density peak clustering[J]. Neural Computing and Applications, 2020, 32 (17): 13465- 13478.
doi: 10.1007/s00521-020-04754-5 |
| 22 | ABDOLLAHZADEH B , GHAREHCHOPOGH F S , MIRJALILI S . African vultures optimization algorithm: a new nature-inspired metaheuristic algorithm for global optimization problems[J]. Computers & Industrial Engineering, 2021, 158, 107408. |
| 23 | YANG Xinshe . Nature-inspired metaheuristic algorithms[M]. Beckington: Luniver Press, 2010. |
| 24 | DUA D, KARRA TANISKIDOU E. UCI machine learning repository[EB/OL]. (2023-11-13)[2023-11-13]. http://archive.ics.uci.edu/ml. |
| 25 |
CHANG Hong , YEUNG D Y . Robust path-based spectral clustering[J]. Pattern Recognition, 2008, 41 (1): 191- 203.
doi: 10.1016/j.patcog.2007.04.010 |
| 26 |
GIONIS A , MANNILA H , TSAPARAS P . Clustering aggregation[J]. ACM Transactions on Knowledge Discovery From Data(TKDD), 2007, 1 (1): 4.
doi: 10.1145/1217299.1217303 |
| 27 |
SUO Mingliang , ZHU Baolong , ZHOU Ding , et al. Neighborhood grid clustering and its application in fault diagnosis of satellite power system[J]. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2019, 233 (4): 1270- 1283.
doi: 10.1177/0954410017751991 |
| 28 | JAIN A K, LAW M H C. Data clustering: a user's dilemma[C]//International Conference on Pattern Recognition and Machine Intelligence. Berlin: Springer, 2005: 1-10. |
| 29 |
VEENMAN C J , REINDERS M J T , BACKER E . A maximum variance cluster algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24 (9): 1273- 1280.
doi: 10.1109/TPAMI.2002.1033218 |
| 30 |
FU L , MEDICO E . FLAME: a novel fuzzy clustering method for the analysis of DNA microarray data[J]. BMC Bioinformatics, 2007, 8 (1): 1- 15.
doi: 10.1186/1471-2105-8-1 |
| [1] | 张一鸣,王国胤,胡军,傅顺. 基于密度峰值和网络嵌入的重叠社区发现[J]. 《山东大学学报(理学版)》, 2021, 56(1): 91-102. |
|