《山东大学学报(理学版)》 ›› 2024, Vol. 59 ›› Issue (7): 95-104.doi: 10.6040/j.issn.1671-9352.1.2023.026
赵峰叙1( ),王健1,林原2,*(),林鸿飞1
),王健1,林原2,*(),林鸿飞1
Fengxu ZHAO1(),Jian WANG1,Yuan LIN2,*(),Hongfei LIN1
摘要:
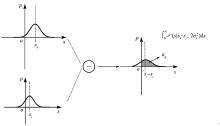
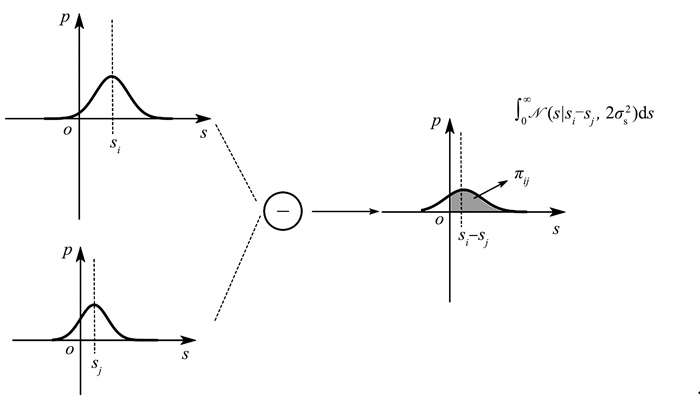
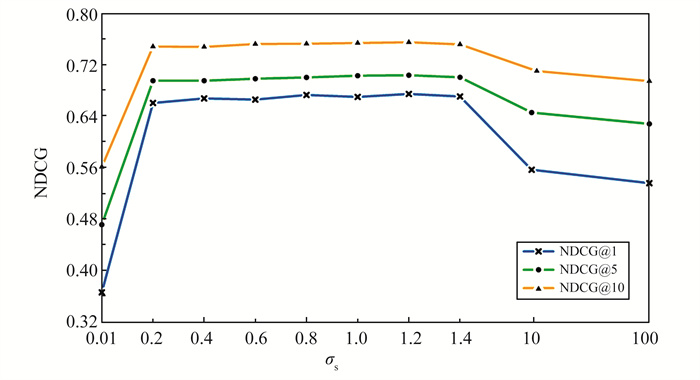
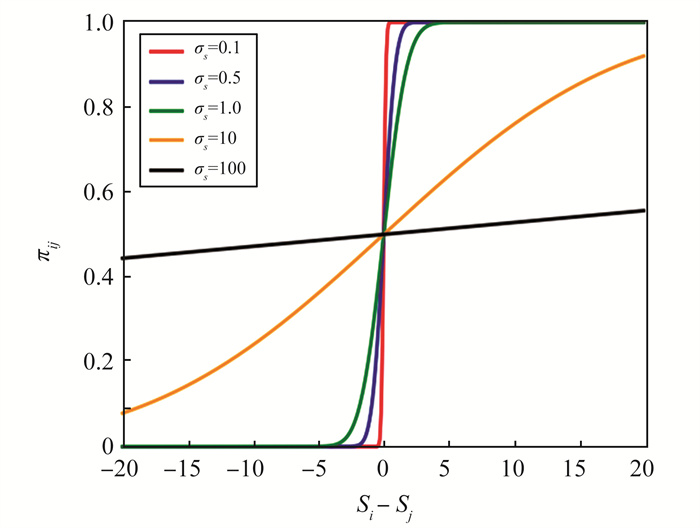
现有的排序学习模型依赖于模型输出的评分来表示文档间的偏序关系。考虑到这种将评分看作单一数值的限制,提出一种概率分布排序学习模型优化方法,引入排序分数的不确定性,以概率分布的形式对排序分数进行平滑,进而将排序分数大小的比较变成对分数偏序关系的概率估计。在此基础上,将该方法应用于排序学习模型RankNet、LambdaRank以及LambdaMART,更合理地拟合模型概率与目标概率之间的差距,从而对排序学习模型进行优化, 并在多个大规模真实数据集上进行实验。结果表明, 经过优化后的模型性能相比于优化前具有显著提高,验证本文方法的有效性。
中图分类号:
| 1 | CHAPELLEO,WUM R.Gradient descent optimization of smoothed information retrieval metrics[J].Information Retrieval,2010,13(3):216-235. |
| 2 | QINTao,LIUTieyan,LIHang.A general approximation framework for direct optimization of information retrieval measures[J].Information Retrieval,2010,13(4):375-397. |
| 3 | TAYLOR M, GUIVER J, ROBERTSON S, et al. SoftRank: optimizing non-smooth rank metrics[C]//Proceedings of the 2008 International Conference on Web Search and Data Minin. Palo Alto: ACM, 2008: 77-86. |
| 4 | VALIZADEGAN H, JIN R, ZHANG R F, et al. Learning to rank by optimizing NDCG measure[C]//Proceedings of the 22nd International Conference on Neural Information Processing Systems. Vancouve: ACM, 2009: 1883-1891. |
| 5 | BRUCH S. An alternative cross entropy loss for learning-to-rank[C]//Proceedings of the Web Conference 2021. Ljubljana: ACM, 2021: 118-126. |
| 6 | BRUCH S, WANG X H, BENDERSKY M, et al. An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance[C]//Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval. Santa Clara: ACM, 2019: 75-78. |
| 7 | BURGES C, SHAKED T, RENSHAW E, et al. Learning to rank using gradient descent[C]//Proceedings of the 22nd International Conference on Machine Learning. Bonn: ACM, 2005: 89-96. |
| 8 | BURGES C J C, RAGNO R, LE Q V. Learning to rank with nonsmooth cost functions[C]//Proceedings of the 19th International Conference on Neural Information Processing Systems. Berlin: Springer, 2006: 193-200. |
| 9 | BURGESC J C.From RankNet to LambdaRank to LambdaMART: an overview[J].Learning,2010,11(81):23-581. |
| 10 | SUN Zhengya, QIN Tao, TAO Qing, et al. Robust sparse rank learning for non-smooth ranking measures[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Boston: ACM, 2009: 259-266. |
| 11 | CHAPELLE O, CHANG Y. Yahoo! learning to rank challenge overview[C]//Proceedings of the 2010 International Conference on Yahoo! Learning to Rank Challenge. Haifa: ACM, 2010: 1-24. |
| 12 | NALLAPATI R. Discriminative models for information retrieval[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Sheffield: ACM, 2004: 64-71. |
| 13 | LI P, BURGES C, WU Q. McRank: learning to rank using multiple classification and gradient boosting[C]//Proceedings of Advances in Neural Information Processing Systems 20 (NIPS 2007). Columbia: Curran Associates, Inc., 2007: 845-852. |
| 14 | JOACHIMS T. Optimizing search engines using clickthrough data[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Edmonton: ACM, 2002: 133-142. |
| 15 | BURGES C, SHAKED T, RENSHAW E, et al. Learning to rank using gradient descent[C]//Proceedings of the 22nd International Conference on Machine Learning. Bonn: ACM, 2005: 89-96. |
| 16 | FREUNDY,IYERR,SCHAPIRER E,et al.An efficient boosting algorithm for combining preferences[J].Journal of Machine Learning Research,2003,4(6):933-969. |
| 17 | XU Jun, LI Hang. AdaRank: a boosting algorithm for information retrieval[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Amsterdam: ACM, 2007: 391-398. |
| 18 | CAO Zhe, QIN Tao, LIU Tieyan, et al. Learning to rank: from pairwise approach to listwise approach[C]//Proceedings of the 24th International Conference on Machine Learning. Corvalis: ACM, 2007: 129-136. |
| 19 | QINT,ZHANGX D,TSAIM F,et al.Query-level loss functions for information retrieval[J].Information Processing & Management,2008,44(2):838-855. |
| 20 | AI Q Y, WANG X H, BRUCH S, et al. Learning groupwise multivariate scoring functions using deep neural networks[C]//Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval. Santa Clara: ACM, 2019: 85-92. |
| 21 | QIN Zhen, YAN Le, ZHUANG Honglei, et al. Are neural rankers still outperformed by gradient boosted decision trees?[C/OL]//International Conference on Learning Representations. 2021: 1-16. https://openreview.net/pdf?id=Ut1vF_q_vC. |
| 22 | AI Qingyao Y, BI Keping, GUO Jiafeng, et al. Learning a deep listwise context model for ranking refinement[C]//SIGIR'18: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. Ann Arbor: ACM, 2018: 135-144. |
| 23 | BRUCH S, ZOGHI M, BENDERSKY M, et al. Revisiting approximate metric optimization in the age of deep neural networks[C]//Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Paris: ACM, 2019: 124-1244. |
| 24 | PANG Liang, XU Jun, AI Qingyao, et al. Setrank: learning a permutation-invariant ranking model for information retrieval[C]//SIGIR'20: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 499-508. |
| 25 | QIN Tao, LIU Tieyan. Introducing LETOR 4.0 datasets[EB/OL]. (2013-01-09)[2023-10-18]. http://arxiv.org/abs/1306.2597. |
| 26 | DATOD,LUCCHESEC,NARDINIF M,et al.Fast ranking with additive ensembles of oblivious and non-oblivious regression trees[J].ACM Transactions on Information Systems (TOIS),2016,35(2):1-31. |
| 27 | WANG X H, LI C, GOLBANDI N, et al. The LambdaLoss framework for ranking metric optimization[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. Torino: ACM, 2018: 1313-1322. |
| [1] | 赵亚琪,任芳国. 关于矩阵的表示及其在熵中应用[J]. 《山东大学学报(理学版)》, 2021, 56(11): 97-104. |
| [2] | 杨光波,王才士,罗艳,王燕燕,南雪琪. 有限偶圈图上的 2-嵌入交错量子游荡[J]. 《山东大学学报(理学版)》, 2021, 56(1): 52-59. |
| [3] | 王佳麒,杨沐昀,赵铁军,赵臻宇. 检务文书检索数据集的构建[J]. 《山东大学学报(理学版)》, 2020, 55(7): 81-87. |
| [4] | 王凯,洪宇,邱盈盈,王剑,姚建民,周国栋. 一种查询意图边界检测方法研究[J]. 山东大学学报(理学版), 2017, 52(9): 13-18. |
| [5] | 曹蓉,黄金柱,易绵竹. 信息检索—DARPA人类语言技术研究的最终指向[J]. 山东大学学报(理学版), 2016, 51(9): 11-17. |
| [6] | 孟烨,张鹏,宋大为. 探索数据集特征与伪相关反馈的平衡参数之间的关系[J]. 山东大学学报(理学版), 2016, 51(7): 18-22. |
| [7] | 张文雅,宋大为,张鹏. 面向垂直搜索基于本体的可读性计算模型[J]. 山东大学学报(理学版), 2016, 51(7): 23-29. |
| [8] | 李胜东, 吕学强, 孙军, 施水才. Lucene全文索引效率的改进[J]. 山东大学学报(理学版), 2015, 50(07): 76-79. |
| [9] | 许洁萍1,殷宏宇1,范子文2. 基于近似子乐句的翻唱歌曲识别研究[J]. J4, 2013, 48(7): 68-71. |
| [10] | 孙静宇,陈俊杰,余雪丽,李鲜花. 协同Web搜索综述[J]. J4, 2011, 46(5): 9-15. |
| [11] | 庞观松,张黎莎,蒋盛益*,邝丽敏,吴美玲. 一种基于名词短语的检索结果多层聚类方法[J]. J4, 2010, 45(7): 39-44. |
| [12] | 万海平,何华灿 . 基于谱图的维度约简及其应用[J]. J4, 2006, 41(3): 58-60 . |
| [13] | 王太峰,袁平波,荚济民,俞能海 . 基于新闻环境的人物肖像检索[J]. J4, 2006, 41(3): 5-10 . |
| [14] | 付雪峰,刘邱云,王明文 . 基于互信息的粗糙集信息检索模型[J]. J4, 2006, 41(3): 116-119 . |
| [15] | 宋春芳,石冰 . 一种基于关联规则的搜索引擎结果聚类算法[J]. J4, 2006, 41(3): 61-65 . |
|