《山东大学学报(理学版)》 ›› 2024, Vol. 59 ›› Issue (3): 27-36, 50.doi: 10.6040/j.issn.1671-9352.4.2023.040
孙嘉睿( ),杜明晶*()
),杜明晶*()
Jiarui SUN(),Mingjing DU*()
摘要:
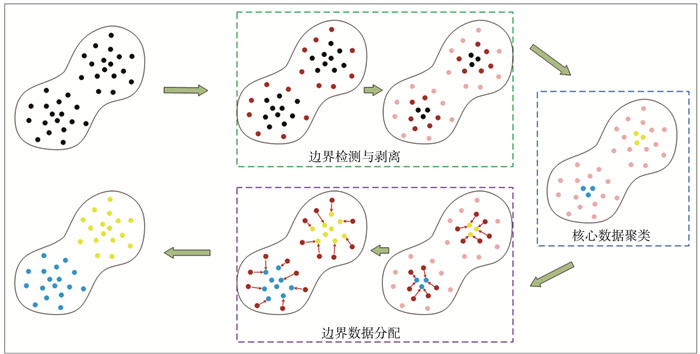
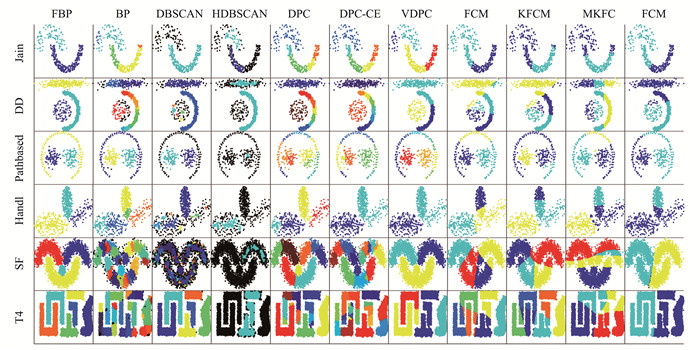
提出了一种模糊边界剥离聚类(fuzzy border-peeling clustering, FBP)算法。首先, 采用了一种基于Cauchy核的动态密度估计方式来计算数据点密度; 然后, 使用逐层剥离策略区分边界数据和核心数据; 接着, 利用核心数据间的可达性实现核心区域聚类; 最后, 采用模糊分配策略实现边界数据的软划分。在人工数据集和真实数据集上与10种算法(包含6种密度聚类算法和4种模糊聚类算法)作了对比。实验结果表明, 在所有数据集上, FBP的调整兰德系数ARI指标平均提高了21%~60%, FBP的标准化互信息NMI指标平均提升了12%~47%, 基于Cauchy核和模糊分配策略优化后的边界剥离聚类算法显著提高了聚类的准确性。
中图分类号:
| 1 | 徐晓, 丁世飞, 丁玲. 密度峰值聚类算法研究进展[J]. 软件学报, 2022, 33 (5): 1800- 1816. |
| XU Xiao , DING Shifei , DING Ling . Survey on density peaks clustering algorithm[J]. Journal of Software, 2022, 33 (5): 1800- 1816. | |
| 2 |
PENG D , GUI Z , WANG D , et al. Clustering by measuring local direction centrality for data with heterogeneous density and weak connectivity[J]. Nature Communications, 2022, 13 (1): 5455.
doi: 10.1038/s41467-022-33136-9 |
| 3 | ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. Menlo Park: AAAI Press, 1996: 226-231. |
| 4 | CAMPELLO R J, MOULAVI D, SANDER J. Density-based clustering based on hierarchical density estimates[C]//Proceedings of the 17th Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin: Springer, 2013: 160-172. |
| 5 |
RODRIGUEZ A , LAIO A . Clustering by fast search and find of density peaks[J]. Science, 2014, 344 (6191): 1492- 1496.
doi: 10.1126/science.1242072 |
| 6 |
CHEN H , LIANG M , LIU W , et al. An approach to boundary detection for 3D point clouds based on dbscan clustering[J]. Pattern Recognition, 2022, 124, 108431.
doi: 10.1016/j.patcog.2021.108431 |
| 7 |
OUYANG T , PEDRYCZ W , PIZZI N J . Rule-based modeling with dbscan-based information granules[J]. IEEE Transactions on Cybernetics, 2021, 51 (7): 3653- 3663.
doi: 10.1109/TCYB.2019.2902603 |
| 8 |
LU J , ZHAO Y , TAN K L , et al. Distributed density peaks clustering revisited[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34 (8): 3714- 3726.
doi: 10.1109/TKDE.2020.3034611 |
| 9 |
RASOOL Z , ZHOU R , CHEN L , et al. Index-based solutions for efficient density peak clustering[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34 (5): 2212- 2226.
doi: 10.1109/TKDE.2020.3004221 |
| 10 | 盛锦超, 杜明晶, 李宇蕊, 等. 结合柯西核的分类型数据密度峰值聚类算法[J]. 计算机工程与应用, 2022, 58 (18): 162- 171. |
| SHENG Jingchao , DU Mingjing , LI Yurui , et al. Cauchy kernel-based density peaks clustering algorithm for categorical data[J]. Computer Engineering and Applications, 2022, 58 (18): 162- 171. | |
| 11 |
AVERBUCH-ELOR H , BAR N , COHEN-OR D . Border-peeling clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42 (7): 1791- 1797.
doi: 10.1109/TPAMI.2019.2924953 |
| 12 | ANKERST M, BREUNIG M M, KRIEGEL H P, et al. Optics: ordering points to identify the clustering structure[C]//Proceedings of the 1999 International Conference on Management of Data. New York: ACM, 1999: 49-60. |
| 13 |
GUO W , WANG W , ZHAO S , et al. Density peak clustering with connectivity estimation[J]. Knowledge-Based Systems, 2022, 243, 108501.
doi: 10.1016/j.knosys.2022.108501 |
| 14 |
WANG Y , WANG D , ZHOU Y , et al. VDPC: variational density peak clustering algorithm[J]. Information Sciences, 2023, 621, 627- 651.
doi: 10.1016/j.ins.2022.11.091 |
| 15 |
DU M , WANG R , JI R , et al. Robp a robust border-peeling clustering using Cauchy kernel[J]. Information Sciences, 2021, 571, 375- 400.
doi: 10.1016/j.ins.2021.04.089 |
| 16 | 陈延伟, 赵兴旺. 基于边界点检测的变密度聚类算法[J]. 计算机应用, 2022, 42 (8): 2450- 2460. |
| CHEN Yanwei , ZHAO Xingwang . Varied density clustering algorithm based on border point detection[J]. Journal of Computer Applications, 2022, 42 (8): 2450- 2460. | |
| 17 |
张柏恺, 杨德刚, 冯骥. 一种去除聚类数量k和邻域参数c设置的自适应聚类算法[J]. 计算机工程与科学, 2021, 43 (10): 1838- 1847.
doi: 10.3969/j.issn.1007-130X.2021.10.018 |
|
ZHANG Bokai , YANG Degang , FENG Ji . A self-adaptive clustering algorithm without neighborhood parameter k and cluster number c[J]. Computer Engineering & Science, 2021, 43 (10): 1838- 1847.
doi: 10.3969/j.issn.1007-130X.2021.10.018 |
|
| 18 | DUNN J C . A fuzzy relative of the isodata process and its use in detecting compact well-separated clusters[J]. Journal of Cybernetics, 1973, 3, 32- 57. |
| 19 | KARAYIANNIS N B. Meca: maximum entropy clustering algorithm[C]//Proceedings of 3rd IEEE International Conference on Fuzzy Systems. Piscataway: IEEE, 1994: 630-635. |
| 20 | GAN G, WU J, YANG Z. A fuzzy subspace algorithm for clustering high dimensional data[C]//Proceedings of 2nd International Conference on Advanced Data Mining and Applications. Berlin: Springer, 2006: 271-278. |
| 21 | FAZENDEIRO P , DE OLIVEIRA J V . Observer-biased fuzzy clustering[J]. IEEE Transactions on Fuzzy Systems, 2014, 23 (1): 85- 97. |
| 22 | KRISHNAPURAM R , KELLER J M . The possibilistic c-means algorithm: insights and recommendations[J]. IEEE Transactions on Fuzzy Systems, 1996, 4 (3): 385- 393. |
| 23 | ZHANG D Q , CHEN S C . Clustering incomplete data using kernel-based fuzzy c-means algorithm[J]. Neural Processing Letters, 2003, 18 (3): 155- 162. |
| 24 | HUANG H C , CHUANG Y Y , CHEN C S . Multiple kernel fuzzy clustering[J]. IEEE Transactions on Fuzzy Systems, 2011, 20 (1): 120- 134. |
| 25 | DING S , DU M , SUN T , et al. An entropy-based density peaks clustering algorithm for mixed type data employing fuzzy neighborhood[J]. Knowledge-Based Systems, 2017, 133, 294- 313. |
| [1] | 万润泽1,雷建军1,袁操2. 基于模糊聚类理论的无线传感器节点休眠优化策略[J]. J4, 2013, 48(09): 17-21. |
| [2] | 付雪峰,刘邱云,王明文 . 基于互信息的粗糙集信息检索模型[J]. J4, 2006, 41(3): 116-119 . |
|